
Cyfrowe archiwa pękają w szwach
Firmy natrafiają na coraz większe trudności związane z zarządzaniem cyfrowymi zasobami. Jednym z największych wyzwań jest archiwizacja dużych zbiorów danych.

Dyrektywy europejskie sprzyjają renesansowi bibliotek taśmowych.
Przedsiębiorstwa gromadzą dane, wychodząc z założenia, że zawsze mogą się do czegoś przydać. Zresztą w taki sam sposób postępują użytkownicy indywidualni. Jednak o ile ci ostatni na swoich komputerach czy domowych NAS-ach przechowują maksymalnie kilka terabajtów danych, o tyle średnie i duże firmy zgłaszają zapotrzebowanie na przestrzeń liczoną w petabajtach, a nawet eksabajtach. Najwięcej danych generują urządzenia w sieci IoT, aplikacje naukowe oraz inżynieryjne, media, monitoring wizyjny czy modele sztucznej inteligencji. W tych obszarach ilość danych rośnie niemal w tempie wykładniczym, co obciąża firmowe repozytoria, a tym samym budżety IT.
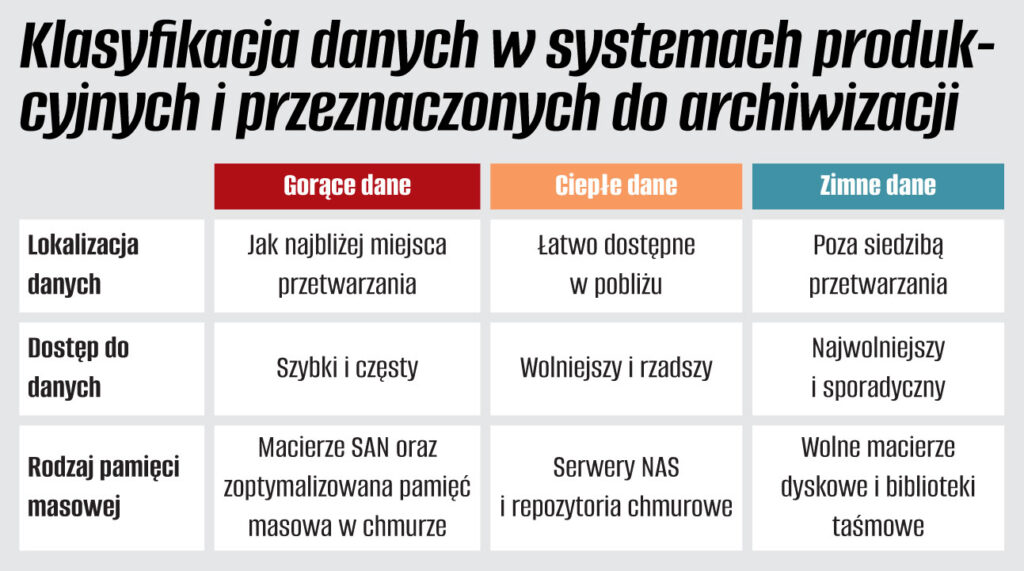
Jeszcze do niedawna pod pojęciem cyfrowej archiwizacji kryło się przechowywanie danych przez okres od kilku miesięcy do kilkunastu lat. Na ogół były to nikomu niepotrzebne zasoby, które musiały znaleźć się w cyfrowym archiwum ze względu na regulacje i rozporządzenia prawne. Dlatego od lat funkcjonuje podział na dane gorące i zimne. Gorące znajdują się bardzo blisko „ciepła”, a więc obracających się dysków i procesorów, zaś zimne spoczywają na tych dyskach lub taśmach, które są ukryte gdzieś daleko na półce.
– Szybki dostęp do zarchiwizowanych danych był często czynnikiem drugoplanowym. Dlatego w przypadku rozwiązań archiwizacyjnych dopuszczano wykorzystywanie nośników off-line, takich jak taśmy magnetyczne. Dzisiaj kwestie szybkiego wyszukiwania danych oraz dostępu stają się coraz bardziej istotne, a to w dużym stopniu zależy od procesu i sposobu ich archiwizacji – tłumaczy Krzysztof Lorant, Pure Storage Business Development Manager w TD Synnex.
W rezultacie proste i czytelne podziały zaczynają się nieco zacierać. Gorące dane to takie, do których potrzebny jest szybki dostęp (w przeciwieństwie do chłodnych). Jednak, jak do tej pory, nie doczekano się standardowej definicji określających „ciepło” i „zimno”.
Segregacja danych
Według klasycznej szkoły w ciągu pierwszego miesiąca od utworzenia danych, aż 80 proc. z nich jest używana sporadycznie lub w ogóle. Dlatego zaleca się zachowanie 20 proc. aktywnych danych na nośnikach flash, zaś resztę na HDD lub taśmach. Niestety, tendencje szybko się zmieniają, bowiem firmy wykorzystują dane do analiz w czasie rzeczywistym czy zasilania nimi systemów AI.
Najczęstszym sposobem określenia czy zbiór danych jest wystarczający, jest zastosowanie reguły 10-krotności. Zasada ta oznacza, że ilość danych wejściowych (czyli liczba przykładów) powinna być dziesięciokrotnie większa niż liczba parametrów w zestawie danych. Przykładowo, jeśli algorytm ma odróżniać obrazy ryb od krokodyli na podstawie tysiąca parametrów, do wytrenowania modelu potrzeba dziesięć tysięcy zdjęć.
– Dostępne rozwiązania w zdecydowanej większości zapewniają na etapie archiwizacji odpowiednią klasyfikację treści, a także bazujące na AI i ML obudowywanie plików w odpowiednie metadane oraz słowa kluczowe. Nie wystarczy już wyłącznie platforma sprzętowa do przechowywania odpowiedniej ilości danych. Musi być dostarczana w komplecie z odpowiednim oprogramowaniem – wyjaśnia Krzysztof Lorant.
Na rynku nie brakuje produktów przeznaczonych do zarządzania danymi znajdującymi się na różnych urządzeniach, najczęściej serwerach NAS. Systemy takie identyfikują dane, a następnie przenoszą je na bardziej ekonomiczną platformę, która może znajdować się w środowisku chmury publicznej. Wraz z przyrostem zasobów cyfrowych, firmy popełniają kardynalne błędy polegające na kupowaniu przestrzeni dyskowej bądź traktowaniu jej jako taniej szafki do magazynowania plików.
Podobne artykuły

Alternatywa dla chmury publicznej
Niektórzy analitycy zapowiadali, że 2023 będzie rokiem repatriacji z chmury publicznej. Tak się nie stało, co nie zmienia faktu, iż wiele firm przechowuje i przetwarza swoje dane w środowisku lokalnym.

Dystrybutorzy liczą na poprawę koniunktury
Dystrybutorzy, ze względu na szereg czynników prowzrostowych, oczekują, że już w pierwszej połowie roku nastąpi wzrost wydatków firm i konsumentów na rozwiązania ICT. Na przeszkodzie może stanąć jedynie trudna do przewidzenia sytuacja międzynarodowa.

Alternatywa dla chmury publicznej
Część analityków zapowiadała, że 2023 ma być rokiem repatriacji z chmury publicznej. Tak się nie stało, co nie zmienia faktu, iż wiele firm przechowuje i przetwarza swoje dane w środowisku lokalnym.