
Ochrona danych: czas na kolejne kroki
W trudnych czasach stosowanie mechanizmów zabezpieczania danych nabiera dodatkowego znaczenia. Producenci rozwiązań zdają sobie z tego sprawę i starają się wzbogacać ofertę o techniczne nowinki.

Hybrydowy model pracy stał się jednym z motorów napędowych BaaS.
Spokojnie, to tylko awaria
Najczęstszą przyczyną przestojów infrastruktury IT były w ubiegłym roku cyberataki oraz błędy ludzkie. Jak wynika z raportu Veeam Data Protection Trends 2022, aż 69 proc. firm z Europy Wschodniej ucierpiało w wyniku działania oprogramowania ransomware, a poszkodowane przedsiębiorstwa nie były w stanie odzyskać średnio 32 proc. utraconych danych. Natomiast błędy ludzkie, w tym nieumyślne usunięcie plików, stanowią 49 proc. przypadków prowadzących do paraliżu systemów IT.
Firmy muszą być przygotowane na czarny scenariusz, aczkolwiek dobry plan powinien uwzględniać specyfikę działania przedsiębiorstwa bądź instytucji. Dla niektórych firm, na przykład z branży e-commerce, spodziewany czas powrotu do sytuacji sprzed awarii liczy się w minutach, a dla innych – w tygodniach. Każdy przypadek trzeba rozpatrywać indywidualnie, z uwzględnieniem przynajmniej kilku czynników.
– Zakład wulkanizacyjny poradzi sobie bez IT przez kilka dni. Ale prędzej czy później brak dostępu do bazy danych klientów czy dokumentów online nawet tego rodzaju firmie zacznie dawać się we znaki. Dlatego należy zastanowić się, co może stać się w przypadku awarii infrastruktury IT i po jakim czasie taki stan zacznie negatywnie wpływać na prowadzony biznes. Odpowiedzi na oba pytania ułatwią dobór odpowiednich komponentów, a tym samym pozwolą przywrócić systemy do działania w oczekiwanym czasie – tłumaczy Wojciech Cegliński, Channel Manager Poland and Baltics w Veeam Software.
Tak czy inaczej, firmy będą dążyć do tego, aby wskaźnik RTO, który określa czas przywrócenia infrastruktury IT po awarii, stawał się coraz niższy. Niejednokrotnie zdarza się, że dostępność definiowana przez użytkowników określona jest na poziomie minut, a nawet sekund, co wymaga inwestycji w systemy wysokiej dostępności (high availability), realizujące funkcje natychmiastowego przywracania (instant restore). Wojciech Cegliński przyznaje, że jeszcze do niedawna klienci uśmiechali się, kiedy apelował do nich, aby dokładnie przemyśleli wartości RTO oraz RPO. W ostatnim czasie przedsiębiorcy podchodzą do tematu z dużo większą powagą.
– Niedostępność sieci logistyki morskiej, banków, stron ministerstw, służby zdrowia zawsze prowadziła do chaosu i ogromnych strat finansowych, a czasem, jak w ubiegłorocznym przypadku ataku na sieć amerykańskich wodociągów, do zagrożenia życia tysięcy ludzi. To wszystko powoduje, że wzrasta rola systemów do replikacji, rozwiązań backupowych pozwalających szybko odzyskać dane za pomocą kopii migawkowych lub zabezpieczyć informacje cyfrowe w odseparowanym od produkcyjnego środowisku – mówi Przemysław Mazurkiewicz.
Wysoka dostępność vs koszty – sztuka kompromisu
Integratorzy powinni zadbać, aby zarząd każdej, nawet małej czy średniej firmy, był zaangażowany w stworzenie dokumentu polityki i strategii bezpieczeństwa danych. To z niego powinna wynikać taktyka, opisująca zastosowanie konkretnych narzędzi ochronnych, umożliwiających m.in. backup danych oraz ich skuteczne odzyskanie. Im lepiej to zadanie zostanie odrobione, tym większe prawdopodobieństwo sukcesu, gdy przyjdzie zmierzyć się z sytuacją kryzysową – rozległą awarią lub katastrofą naturalną, jak pożar, zalanie czy zawalenie budynku.
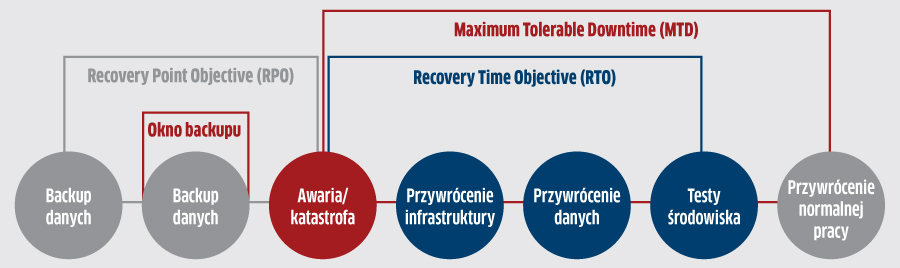
Elementem polityki bezpieczeństwa jest plan przeciwdziałania skutkom katastrof (disaster recovery, DR), który powinien odzwierciedlać wymagania stawiane przez jednostki biznesowe firmy. Przy jego tworzeniu konieczne jest określenie przez zarząd i informatyków czterech ważnych parametrów:
- Recovery Point Objective, RPO – określa moment w przeszłości, w którym po raz ostatni została wykonana kopia danych. Wszystkie nowe dane, wytworzone lub zmodyfikowane po tym momencie, zostaną utracone. Maksymalna długość zdefiniowanego w ten sposób czasu zależy głównie od charakteru działalności firmy i jest różna zarówno dla poszczególnych przedsiębiorstw, działów biznesowych, jak też serwerów i usług (jednym wystarczy kopia sprzed tygodnia, inni zaś potrzebują danych sprzed kilkunastu sekund). Im krótszy jest ten czas, tym większe obciążenie systemu backupowego i koszt jego obsługi.
- Recovery Time Objective, RTO – maksymalny czas po wystąpieniu awarii, potrzebny do przywrócenia działania aplikacji, systemów i procesów biznesowych. Określając parametr RTO należy doprowadzić do kompromisu między potencjalnymi stratami, a kosztami rozwiązania umożliwiającego jak najszybsze odtworzenie stanu sprzed awarii.
- Maximum Tolerable Downtime, MTD – maksymalny akceptowalny przez zarząd firmy czas, przez który nie wszystkie środowiska IT mogą działać w pełni sprawnie lub z ograniczoną wydajnością. Jest dłuższy od czasu RTO ze względu na konieczność przeprowadzenia testów po procesie odzyskania systemów i danych.
- Okno backupu – przedział czasu, w którym można wykonać kopię z zachowaniem spójności danych, bez utrudniania pracy użytkownikom systemów, np. w wyniku spadku wydajności komputerów lub serwerów.
W przypadku coraz większej liczby przedsiębiorstw okna backupu danych z serwerów kurczą się – niechętnie wstrzymywana jest ich praca bądź obniżana wydajność na potrzeby wykonania backupu. Znacznie skracają się też czasy RPO/RTO/MTD, bowiem przedsiębiorcy nie dopuszczają myśli o utracie jakichkolwiek danych, zaś w przypadku konieczności skorzystania z backupu chcą mieć dostęp do zabezpieczonych informacji jak najszybciej. Dlatego rośnie popularność kopii wykonywanych w trybie ciągłym (Continuous Data Protection, CDP), mimo niemałych kosztów związanych z tym mechanizmem.
Warto także podkreślić, że replikacja danych nie powinna być traktowana jako alternatywa dla backupu. Ma bowiem podstawową wadę – nie chroni przed skasowaniem danych lub ich utratą, np. w wyniku działania wirusa lub zaszyfrowania przez ransomware (dane zostaną usunięte zarówno na oryginalnym nośniku, jak i w jego replice).

Podobne artykuły

Prawo stwarza szansę dla integratorów
Przedsiębiorcy zgłaszają potrzebę i chęć współpracy z zewnętrznymi zaufanymi ekspertami, aby pokonać bariery i wdrożyć szyfrowanie w kluczowych dla swojego funkcjonowania obszarach.

Dane torują drogę do innowacji
W lutowej edycji konferencji Technology Live! wzięli udział czterej dostawcy: Keepit, Hammerspace, Nimbus Data oraz Own Company. Przedstawili kilka interesujących nowinek związanych z ochroną oraz przetwarzaniem danych.

NIS2 jako szansa na biznes
W październiku tego roku upływa termin przyjęcia przez wszystkie państwa członkowskie Unii Europejskiej dyrektywy NIS2. Czy dostawcy mogą liczyć na wzrost sprzedaży usług i rozwiązań cybersecurity?